Recent progress in robotic manipulation has been driven by a wide range of approaches, from large end-to-end policies trained on demonstrations or reinforcement learning, to systems that explicitly compose perception, language, and control components. Each of these paradigms has produced impressive results, but understanding how they relate — and how they can be combined — remains an open and important question.
In this work, we focus on building capable manipulation systems through modular composition. We introduce TiPToP (TiPToP is a Planner That just works on Pixels), a planning-based robotics system that solves complex real-world manipulation tasks directly from raw pixels and natural-language commands. TiPToP composes a Task-and-Motion Planning (TAMP) core with off-the-shelf perception and language models into coherent long-horizon behavior via inference-time search and optimization.
At its core, TiPToP is designed to be easy to setup, modular, and performant. Our system can be deployed on supported hardware in under one hour, and its modular design allows individual components (e.g., perception models) to be improved independently. This modularity also enables extension to novel embodiments and the incorporation of new skills. We benchmark TiPToP through extensive evaluation against \(\pi_{0.5}\text{-DROID}\), a state-of-the-art VLA fine-tuned on 350 hours of embodiment-specific demonstrations. The majority of this evaluation was conducted by an external evaluation team not involved in the development of TiPToP. Over 165 trials in 28 evaluation scenes in the real world and simulation combined, TiPToP (which requires zero robot data) often matches or outperforms \(\pi_{0.5}\text{-DROID}\), particularly on tasks requiring semantic grounding, distractor rejection, and multi-step sequencing. We provide a detailed failure analysis and use it to identify concrete directions for improving individual modules.
In this blog post, we describe the key ingredients of TiPToP and explain how its modular architecture enables compositional generalization across tasks, environments, and embodiments. We discuss current limitations, outline concrete directions for improving individual components, and highlight opportunities for research into tighter integration with large-scale end-to-end learned policies. We hope readers will try TiPToP themselves and build atop it by extending or improving existing modules, or by contributing entirely new ones.
# TiPToP Overview
Video: walk-through of the TiPToP architecture showing the flow from initial image and language instruction through perception, planning, and execution.
TiPToP adopts a modular architecture with separate perception, planning, and execution modules (described below). This modular design enables strong compositional generalization via combining skills in novel ways to operate over unseen objects without any task-specific data or training. Additionally, it affords the ability to improve the overall system by improving specific modules independently. Below, we provide a high-level overview of our different modules. System implementation details, along with a detailed walkthrough, can be found in the Implementation Details page.
1. Perception
The perception module constructs an object-centric 3D scene representation from RGB images and a natural-language instruction. Two branches run in parallel:
- 3D Vision Branch: FoundationStereo estimates depth and produces a dense point cloud. M2T2 predicts 6-DoF grasp poses from this point cloud.
- Semantic Branch: Gemini Robotics-ER 1.5 detects objects and grounds the language instruction to symbolic goals. SAM-2 generates segmentation masks from these detections.
We combine both branches by masking the dense point cloud to extract per-object point clouds, then reconstruct object geometry using convex hull completion. The object meshes are used for collision checking, and we find them to be surprisingly sufficient for a variety of rearrangement tasks given their tendency to overapproximate. The output scene representation contains object meshes, candidate grasps, and symbolic goal propositions.
2. Planning
TiPToP uses cuTAMP , a GPU-parallelized Task and Motion Planning (TAMP) solver, to search over high-level task plans (e.g., sequences of pick and place actions) and to optimize low-level robot motions and gripper actions. cuTAMP is able to optimize thousands of candidate plans in parallel to efficiently find long-horizon solutions that satisfy the grounded goal. It relies on the object-centric scene representation for sampling grasps, collision checking, and checking placement and stability constraints.
3. Execution
We execute the resulting trajectory open-loop, using a joint impedance controller. TiPToP sends joint position and velocity targets, together with gripper commands, directly to the robot without feedback or replanning during execution.
# Evaluation and Results
We evaluated TiPToP on 28 tasks for a total of 165 trials in simulation and the real world, comparing against \(\pi_{0.5}\text{-DROID}\) . The majority of the tasks were evaluated at the University of Pennsylvania by an external team that was not involved in developing TiPToP.
TiPToP in an IsaacLab simulation environment (5x speed)
TiPToP evaluated internally at MIT by system developers (5x speed)
TiPToP evaluated externally at the University of Pennsylvania (10x speed)
Overall, TiPToP achieved a 59.4% success rate over all 28 evaluation tasks compared to \(\pi_{0.5}\text{-DROID}\)'s 33.3%. In terms of task progress — which provides a more fine-grained measure of how close to achieving the goal a particular attempt is — TiPToP achieves 74.6% on average on these tasks compared to \(\pi_{0.5}\text{-DROID}\)'s 52.4%. TiPToP is also faster than \(\pi_{0.5}\text{-DROID}\) and achieves success 37.0% faster per task on average in simulation and real-world tasks where both succeed (unweighted mean over 7 scenes). It is interesting to note that about half of the total execution time of TiPToP is spent in perception and planning and the rest in execution. We divide the results according to task type: 1) single-step pick-and-place, 2) semantic reasoning with distractors, and 3) multi-step manipulation. Full per-scene results tables and videos can be found on our full results page.
Simple Pick-and-Place
On simple single-step pick-and-place tasks, TiPToP and \(\pi_{0.5}\text{-DROID}\) perform comparably in terms of overall success rate, though TiPToP is generally faster. These tasks involve unambiguous objects in uncluttered scenes, making them straightforward for both systems. However, we found that even in these simple scenarios, \(\pi_{0.5}\text{-DROID}\) often idles without making additional progress.
Task: "place the crackers onto the tray" (TiPToP: 5/5, 14.9s avg. \(\pi_{0.5}\text{-DROID}\): 3/5, 32.2s avg.)
Semantic Reasoning and Distractors
As task complexity increases a consistent performance gap emerges. On tasks with distractors and tasks that require semantic reasoning to accurately identify relevant objects, TiPToP outperforms \(\pi_{0.5}\text{-DROID}\) on the majority of scenes. These tasks often involve complex referring expressions (e.g., "the peanut butter crackers", "the Minecraft creeper toy", "the cup pointed to by the arrow"), multiple visually similar objects, or color-based sorting. TiPToP uses a large VLM to translate visual observations and language instructions into symbolic goals. We suspect that this explicit grounding step enables TiPToP to correctly identify objects amid distractors and to interpret complex referring expressions that \(\pi_{0.5}\text{-DROID}\) has no mechanism to explicitly reason about.
For example, when asked to "place the peanut butter crackers onto the tray" in a scene with multiple cracker packets, TiPToP successfully identifies the correct packet using Gemini's grounding capabilities, while \(\pi_{0.5}\text{-DROID}\) consistently fails on all trials. In tasks requiring reasoning about distractors or semantics, TiPToP achieves 62.4% success rate compared to \(\pi_{0.5}\text{-DROID}\)'s 25.9%.
Task: "place the peanut butter crackers onto the tray" (TiPToP: 5/5, \(\pi_{0.5}\text{-DROID}\): 0/5)
Multi-Step Manipulation
On the multi-step evaluation tasks, TiPToP also outperforms \(\pi_{0.5}\text{-DROID}\). These tasks include constrained packing (where objects must be arranged in specific configurations) and tasks that require moving obstacle objects out of the way before placing target objects. TiPToP uses cuTAMP, a Task and Motion Planner, to decompose multi-step goals into a sequence of feasible pick-and-place actions with collision-free motion plans. This allows TiPToP to reason about the ordering of actions and their constraints (e.g., stable placement, kinematic feasibility, no collisions). By contrast, \(\pi_{0.5}\text{-DROID}\) must implicitly discover this multi-step structure from the language command alone.
For example, when packing coffee pods onto a tray obstructed by a can, TiPToP plans to first move the can out of the way, then place the pods. Without this explicit decomposition mechanism, \(\pi_{0.5}\text{-DROID}\) struggles to execute such sequential reasoning, often attempting to pick objects without first clearing obstacles. TiPToP achieves a 57.5% success rate over all multi-step tasks compared to 15% for \(\pi_{0.5}\text{-DROID}\).
Task: "put the small white aleve bottle into the cardboard tray" (TiPToP: 4/5, \(\pi_{0.5}\text{-DROID}\): 2/5)
Task: "pack the coffee pods onto the rectangular tray" (with obstructing can, TiPToP: 1/5, \(\pi_{0.5}\text{-DROID}\): 0/5)
# Failure Analysis
A key advantage of TiPToP's modularity is the ability to trace failures to specific components. To better understand TiPToP's failure modes, we ran a separate set of 173 trials spanning single-object pick-and-place through long-horizon sequences of up to 5 objects, with varying levels of semantic reasoning and distractor clutter. This breakdown directly informs which modules to prioritize for improvement.
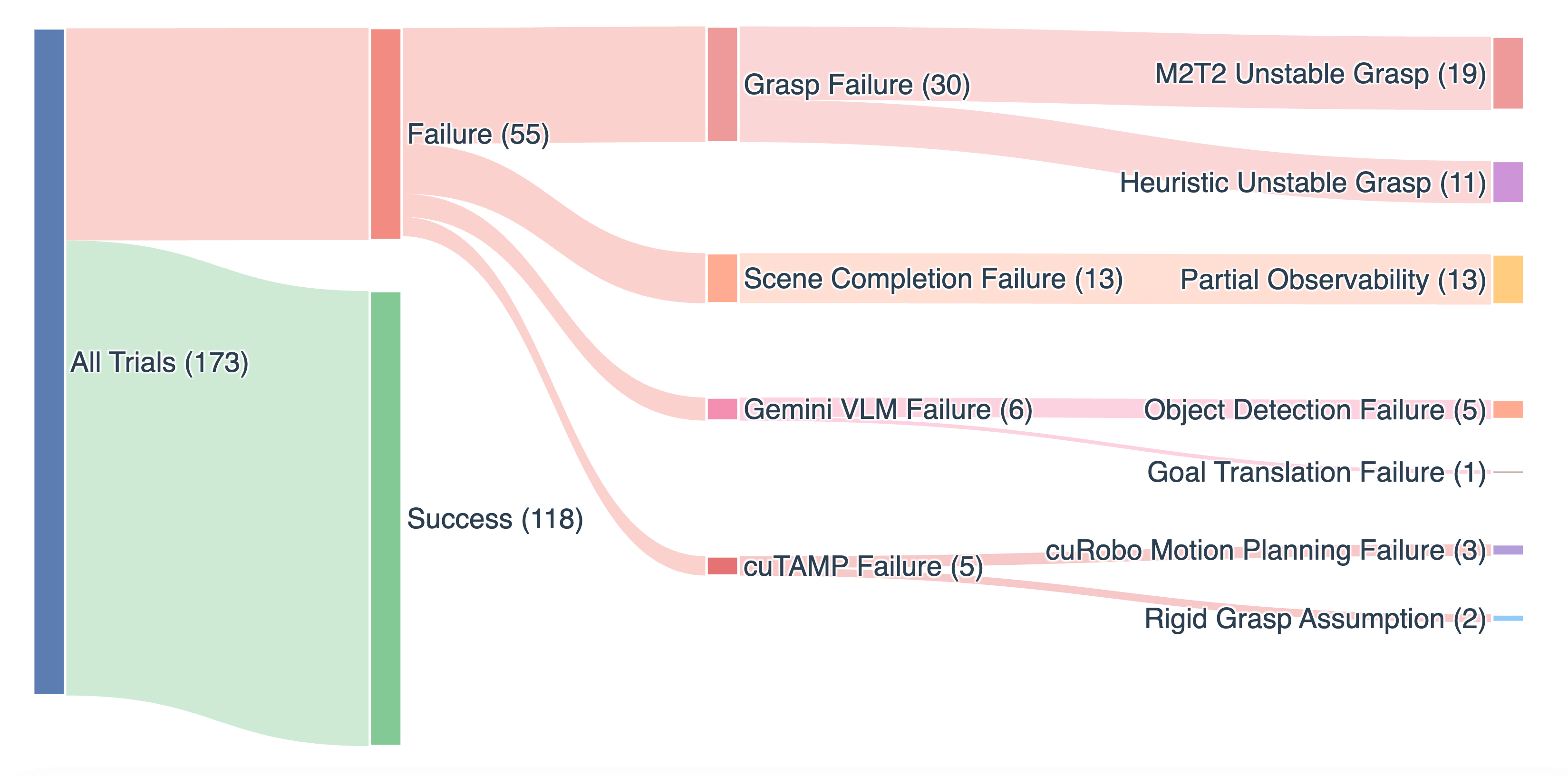
Sankey diagram of TiPToP trial outcomes and failure categories
Grasping failures (30/55). In 19 cases, M2T2 produces high-scoring grasps that fail in execution due to instability or slippage, and in 11 the heuristic fallback sampler similarly produces unstable grasps for objects outside M2T2's predictions.
Scene completion errors (13/55). Partial observability can lead to underapproximated meshes, causing collisions during motion execution that knock or displace objects, leaving the assumed scene state incorrect for later execution steps. Convex hull completion can also overapproximate concave objects (e.g., a banana into a large oval), ruling out otherwise valid grasps during collision checking.
VLM errors (6/55). Gemini fails to detect objects (5 failures) or produces incorrect goal translations (1 failure).
cuTAMP failures (5/55). In 3 cases, the underlying motion planner (cuRobo ) failed to find a viable motion plan within our planning-time budgets. In 2 cases, cuTAMP's rigid grasping assumption was violated.
Compilation of grasping failures (1x speed)

Gemini fails to identify the small orange cube
# Cross-Embodiment Generalization
One key benefit of TiPToP is that the overall architecture is embodiment agnostic. To illustrate this, we deployed TiPToP on a UR5e arm with a RealSense D435 wrist camera. Adapting TiPToP to this new embodiment required:
- The robot URDF
- Collision spheres for the robot geometry, which can be automatically generated using tools like Ballpark or Foam
- A cuRobo configuration file, which includes these collision spheres along with other information including the names of the base link, end-effector link, joints for the configuration space, and self-collision links. See the cuRobo tutorial for more details.
- Localized code changes in cuTAMP to load these new configuration files.
- Localized code changes in TiPToP to interface with the new camera and robot controller.
TiPToP's codebase is designed with abstractions that make adding new camera types or robot controllers straightforward. We were able to make all these updates to support the UR5e with a RealSense camera in around 2-3 hours.
TiPToP deployed on a UR5e arm with a wrist-mounted RealSense D435 camera.
TiPToP has also been deployed on a Trossen WidowX AI arm with a RealSense D405 wrist camera. As with the UR5e, the required changes were localized to robot-specific configuration and interface code, leaving the perception and planning infrastructure untouched.
TiPToP deployed on a Trossen WidowX AI arm (4x speed).
# Extending Beyond Pick-and-Place
TiPToP's modularity also makes it straightforward to extend beyond pick-and-place. To demonstrate this, we added a whiteboard wiping primitive that enables the robot to wipe writing off a surface given an eraser. This required three localized changes, none of which modified the perception or execution infrastructure:
- Semantic branch: We added two new predicates (see our Implementation Details page for more on predicates and how we use them),
IsEraserandIsCleaned, and extended the VLM goal-grounding prompt to translate instructions involving cleaning into conjunctions over these predicates. - Planning: We defined a new
WipeTAMP operator in cuTAMP with preconditions that the robot is holding an eraser and the target is a surface, and an effect that marks the surface as cleaned. The task planner automatically sequences pick then wipe to satisfy anIsCleanedgoal. - Execution: The wiping controller calls the VLM a second time to localize the region of interest (e.g., written text) on the surface via a bounding box query, reprojects the corners into world coordinates using the existing point cloud, then executes a sequence of back-and-forth strokes covering the detected region.
The entire extension was implemented in under a day without modifying any existing perception, planning, or execution code outside of the additions described above. Importantly, adding this new skill does not affect or diminish TiPToP's capabilities involving other skills: the system is able to flexibly compose this new skill with previous ones. For example, given the task instruction "erase the whiteboard and put everything into the bowl", TiPToP picks up the whiteboard marker, puts it in the bowl, then uses the eraser to wipe the whiteboard before placing it in the bowl too.
Task instruction: "erase the whiteboard and put everything into the bowl". TiPToP combines pick-and-place with the whiteboard wiping skill (10x speed).
# Extensions and Future Work
There are several limitations with the current version of TiPToP. Below, we highlight a few major directions for improvement, and leave a more thorough discussion of future directions, as well as current system assumptions, to the Implementation Details page.
Open-loop execution. This is the single most impactful limitation: our failure analysis shows that grasping failures account for over half of all failures, many of which could be recovered from by re-attempting the grasp. The most direct improvement is to re-run perception and planning (i.e., 'execution monitoring') after each pick-and-place step, enabling recovery from failed grasps or unexpected object movement .
Single-viewpoint perception. All task-relevant objects must be at least partially visible from a single wrist-camera pose. This also limits mesh quality: with only one viewpoint, convex hull completion can over- or under-approximate object geometry. Multi-view perception (via active camera movement or additional static cameras) would reduce occlusions and improve shape estimates. Learned shape completion methods such as SAM-3D could replace convex hull approximation with more accurate meshes.
Integrating learned policies. Our experiments show that TiPToP and \(\pi_{0.5}\text{-DROID}\) exhibit complementary failure modes: TiPToP excels at geometric reasoning, long-horizon sequencing, and semantic grounding, but fails when grasps slip or meshes are poorly approximated; \(\pi_{0.5}\text{-DROID}\) benefits from closed-loop reactivity but struggles with multi-step structure, tight constraints, and distractor-rich scenes. This suggests that learned policies such as VLAs could serve as reactive skill primitives within TiPToP, both improving robustness for existing skills and enabling new ones that are difficult to hand-engineer (e.g., folding, cable manipulation) .
Belief-space planning. Extending cuTAMP to operate in belief space would enable reasoning about uncertainty in object poses, grasp outcomes, and partially observable state. This could also enable information-gathering actions (e.g., moving the camera to observe an occluded region before planning) and more robust action selection under perceptual uncertainty .
# Conclusion
We presented TiPToP, a manipulation system designed to be easy to set up, modular, and performant. TiPToP requires zero robot training data yet matches or outperforms \(\pi_{0.5}\text{-DROID}\) over 165 trials in 28 evaluation tasks. TiPToP excels particularly on tasks requiring semantic grounding, distractor rejection, and multi-step sequencing, while also completing tasks faster on average.
TiPToP's modular architecture provides concrete practical advantages. Component-level failure analysis over 173 trials enabled us to trace each failure to specific modules and identify clear directions for improvement. Each component can be independently upgraded: as better depth estimators, grasp predictors, VLMs, or motion planners become available, they can be swapped in without redesigning the entire system. This modularity also enables novel skill integration, as demonstrated by our wiping extension, and generalizes to simulation domains and new embodiments with minimal engineering effort, as shown by our integration with UR5e and WidowX AI arms, each equipped with a RealSense camera.
A central finding of this work is that modular composition of pretrained foundation models with structured planning can produce a highly capable manipulation system without requiring robot-specific training data. The complementary failure profiles of TiPToP and \(\pi_{0.5}\text{-DROID}\) suggest that integrating learned policies as reactive skill primitives within our framework could combine the structured reasoning and semantic grounding of planning with the robustness of closed-loop visuomotor control. We hope that our open-source system, detailed performance analysis, and demonstrations of extensibility will support future research towards broadly competent and generalizable manipulation systems.
# Acknowledgements
We gratefully acknowledge support from NSF grant 2214177; from AFOSR grant FA9550-22-1-0249; from ONR MURI grants N00014-22-1-2740 and N00014-24-1-2603; from the MIT Quest for Intelligence; and from the Robotics and AI Institute.
We thank Ryan Lindeborg for deploying TiPToP on his Trossen WidowX AI and for providing installation and debugging feedback. We thank Jesse Zhang for testing TiPToP at the University of Washington. We thank Wenlong Huang for help setting up FoundationStereo to improve point cloud accuracy, as well as several helpful discussions. We also thank Tom Silver, Chris Agia, Joey Hejna, Karl Pertsch, Danny Driess, and Fabio Ramos for helpful discussions and feedback on earlier drafts of this work.
# Author Contributions
William Shen and Nishanth Kumar contributed equally to this work. William adapted and improved the core cuTAMP system to be suitable (simpler to use, faster) for our purposes. Nishanth implemented the perception interface to Gemini and SAM. Both William and Nishanth worked on integrating additional models (FoundationStereo, M2T2) into the system, packaging all components to be easily used, benchmarking system capabilities, and compiling this post.
Sahit Chintalapudi implemented and packaged the control stack for the Franka Panda and FR3 robots. He also helped run quantitative experiments to investigate TiPToP's failure modes.
Jie Wang led the evaluations conducted at the University of Pennsylvania, and assisted with analysis and experimental design. Christopher Watson set up TiPToP and assisted with evaluations, experimental design and analysis. Edward S. Hu assisted with TiPToP setup and contributed to experimental design and analysis. Dinesh Jayaraman advised the evaluations and provided lab resources.
Jing Cao set up the simulator and ran simulation experiments comparing \(\pi_{0.5}\text{-DROID}\) to TiPToP, and analyzed the results.
Leslie Pack Kaelbling and Tomás Lozano-Pérez provided several helpful system implementation and task suggestions, and strongly encouraged that the code should be easy to install. They also provided several more suggestions for improvement, the bulk of which have been left for future work.
# Citation
Please cite this work using the BibTeX citation:
@misc{shen2026tiptop,
author = {William Shen and Nishanth Kumar and Sahit Chintalapudi and Jie Wang and Christopher Watson and Edward S. Hu and Jing Cao and Dinesh Jayaraman and Leslie Pack Kaelbling and Tom{\'a}s Lozano-P{\'e}rez},
title = {{TiPToP}: A Modular Open-Vocabulary Planning System for Robotic Manipulation},
year = {2026},
month = jan,
url = {https://tiptop-robot.github.io},
note = {Project website}
}# References
© 2026 TiPToP Authors